
lecture5-Note
Type I Error
false positive, "rejected the null" but there is no difference
- Rejecting a true null hypothesis
- Also known as false positive or error
- Concluding there is a difference when there actually is none
- Easy to control
- Decide the probability in advance for a given test
- The standard cutoff is 0.05, meaning there is a 5% chance of a Type I Error
Type two Error
false negative, "failed to reject" bull there is a difference
- Failing to reject a false null hypothesis
- Also known as false negative or error
- Test was not sensitive enough to find a difference when on actually exists
- More difficult to overcome than Type I
- Statistical power is equal to 1 -
- Measure of the sensitivity of the test(increases with larger N)
- Also influenced by experimental design and the size of the effect
- Impossible to know precisely in advance, but you can estimate
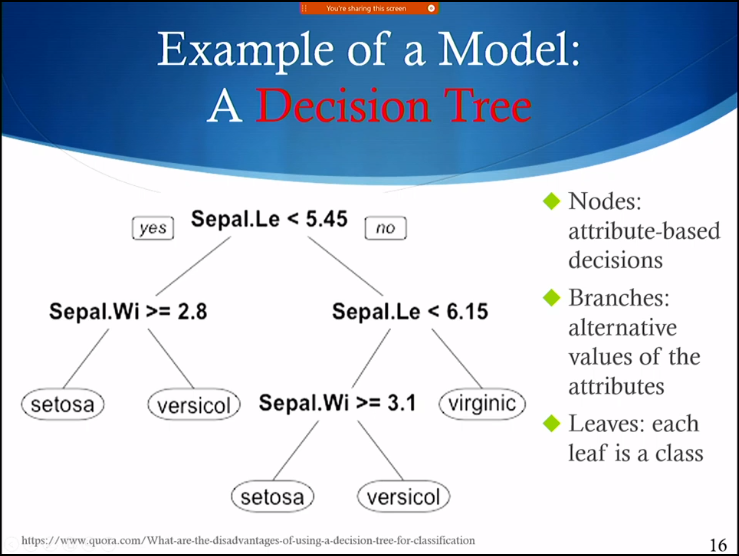
Classification
Model
- Given:
- A set of classes
- Instances (example) of each class
- Generate: A method (aka a model) that when give a new instance it will determine its class
- Instances are described by a set of features (or** attributes**, or variables) and their values
- The class that the instance belongs to is also called its “label”
- Input is a set of “labeled instances”
Model Parameters
- Model parameters
- Model parameters are variables in the algorithm that are used to constrain the model
- Hyper-parameter search: trying out different model parameters to improve the quality of the model
About Classification Tasks
- Classes must be disjoint, each instance belongs to only one class
- Classification tasks are “binary” when there are only two classes
- The classification method will rarely be perfect, it will make mistakes in its classification of new instances
- Classifiers use induction
Training & Evaluating Classification Models
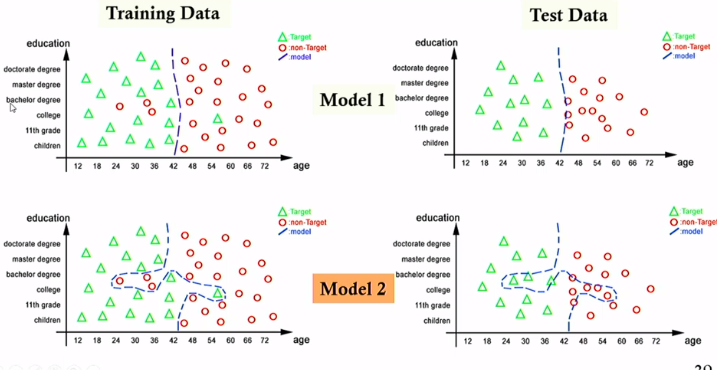
Overfitting
- A model overfits the training data when it is very accurate with that data, and may not do so well with new test data
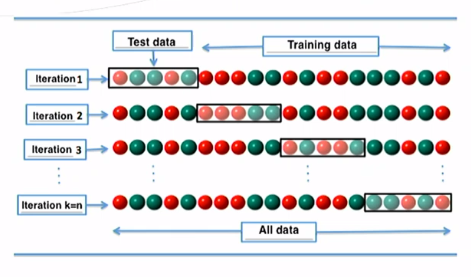
N-fold Cross Validation
- Suppose m labeled instances
- Divide into n subsets of equal size
- Run classifier n times with each of the subsets as the test set
- The rest (n-1) for training
- Each run gives an accuracy result
What affects the performance
- high dimensionality - Large amounts of features
- sparse data - Missing feature values for instances
- Errors in feature values for instances
- Errors in the labels of training instances
- Not enough instances
- Uneven availability of instances in classes
Advanced Techniques for Classification Tasks
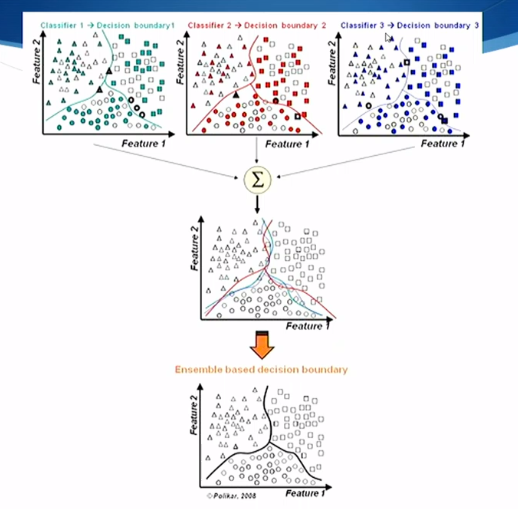
Ensembles
- An ensemble method uses several algorithms that do the same task, and combines their results - “Ensemble learning”
- A combination function joins the results
- Majority vote: each algorithm gets a vote
- Weighted voting: each algorithm’s vote has a weight
- Many other complex combination functions are possible
Clustering, Patterns, and Simulation
Clustering
- Given:
- A set of instances, with feature values
- Often called “feature vectors”
- Optional: target number of cluster (k)
- A set of instances, with feature values
- Find:
- The “best” assignment of instances to clusters
- “Best” : satisfies some optimization criteria
- “clusters” represent similar instances
- The “best” assignment of instances to clusters
K-Means Clustering Algorithm
- User specifies a target number of clusters (k)
- Place randomly k cluster centers
- For each datapoint, attach it to the nearest cluster center
- For each center, find the centroid of all the datapoints attached to it
- Turn the centroids into cluster centers
- Repeat until the sum of all the datapoint distances to the cluster centers is minimized
Learning Approaches
- Supervised Learning
- The training data is annotated with information to help the learning system
- Eg the class for each instance
- The training data is annotated with information to help the learning system
- Unsupervised Learning
- The training data is not annotated with any extra information to help the learning system
- Semi-Supervised Learning
Patterns
- Pattern Detection
- Inputs: Data, A set of patterns
- Output: Matches of the patterns to the data
- Pattern Learning
- Inputs: Data annotated with a set pf patterns
- Output: A set of patterns that appear in the data with some frequency
- Pattern Discovery
- Inputs: Data
- Output: A set of patterns that appear in the data with some frequency
Simulation
- Simulation is an approach to data analysis that uses a mathematical or formal model of a phenomenon to run different scenarios to make predictions
- Simulation models - mathematical or formal model that captures the relationships between a set of variables to characterize a dynamical system
- Models are used to make predictions about hypothetical situations and future states of the system
- Models can have parameters that can be adjusted
- Outputs are compared with observed data to assess quality
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles

Comment
